分位数 パーセンタイル
ここでは分位数(quantiles, クォンタイル)とパーセンタイル(percentiles)について説明します。
考え方の違いで何種類かの計算流儀がありまして、Excel関数には2つの流儀の関数が用意されています。
また、統計解析環境のRの標準ライブラリ関数には9つのタイプの流儀があります。
(こちらの講義)では説明しきれなかった部分の補足になります。
分位数(quantiles)で一番有名なのが四分位数(quartiles, 4-quantiles)クォータイルです。
四分位数とは数量データを順位(rank)で4等分する数のことです。
四分位数は、四分位点、又は、四分位値、と呼ばれることがあります。
分位数で次に良く使われるものがパーセンタイル(percentiles,100-quantiles)です。
パーセンタイルとは数量データを順位で100等分する数のことで、パーセント点、又は、百分位数、とも呼ばれることがあります。
一般にデータを順位で $n$ 等分する数を、$n$分位数($n$-quantiles)クォンタイルと言います。
実は、最小値(minimum)、中央値(median)、最大値(maximum)は、順位で2等分した数のことになりますので、二分位数(2-quantiles)の別名に相当することになります。
また、3等分する三分位数(terciles, 3-quantiles)や、8等分する八分位数(octiles, 8-quantiles)や、10等分する十分位数(deciles, 10-quantiles)など、様々な分位数が存在します。
順位というものはデータを大きさ順に並べた時の順番なので、通常は1番、2番、3番、のように自然数で表現された番号になります。
この順位を 0 から 1 の大きさで表される割合(率)に対応させたものが相対順位(relative rank)というものです。
相対順位は割合(率)なので、分数や小数や百分率で表すことができます。
百分率で表現した相対順位をパーセント順位(percent rank)と呼びます。
この解説では相対順位を文字 $p$ を用いて表します。
分位数と相対順位の関係をまとめると、次のようになります。
ある特定の相対順位に対応するデータの数値が、分位数です。
分位数は、分位値、分位点、などと呼ばれることもあります。
このあたりの関係は、一回だけでも具体的な計算を実行すると理解できますので、最後まで解説を読んでみてください。
| 通常の名称 | 分位数 | 二分位数 | 四分位数 | 八分位数 | パーセンタイル | 相対順位 $p$ |
|---|
| 最小値(最小位数) | 0分位数 | 第0二分位数 | 第0四分位数 | 第0八分位数 | 0パーセンタイル | $0=\frac{0}{1}=\frac{0}{2}=\frac{0}{4}=\frac{0}{8}=\frac{0}{100}$ |
| 0.125分位数 | | | 第1八分位数 | 12.5パーセンタイル | $\frac{1}{8}=\frac{12.5}{100}$ |
| 0.25分位数 | | 第1四分位数 | 第2八分位数 | 25パーセンタイル | $\frac{1}{4}=\frac{2}{8}=\frac{25}{100}$ |
| 0.375分位数 | | | 第3八分位数 | 37.5パーセンタイル | $\frac{3}{8}=\frac{37.5}{100}$ |
| 中央値(中位数) | 0.5分位数 | 第1二分位数 | 第2四分位数 | 第4八分位数 | 50パーセンタイル | $\frac{1}{2}=\frac{2}{4}=\frac{4}{8}=\frac{50}{100}$ |
| 0.625分位数 | | | 第5八分位数 | 62.5パーセンタイル | $\frac{5}{8}=\frac{62.5}{100}$ |
| 0.75分位数 | | 第3四分位数 | 第6八分位数 | 75パーセンタイル | $\frac{3}{4}=\frac{6}{8}=\frac{75}{100}$ |
| 0.875分位数 | | | 第7八分位数 | 87.5パーセンタイル | $\frac{7}{8}=\frac{87.5}{100}$ |
| 最大値(最大位数) | 1分位数 | 第2二分位数 | 第4四分位数 | 第8八分位数 | 100パーセンタイル | $1=\frac{1}{1}=\frac{2}{2}=\frac{4}{4}=\frac{8}{8}=\frac{100}{100}$ |
言葉の使い方がややこしいのですが、次のように考えるとなんとなく納得できます。
英語の「quater」は「半分の半分」つまり「四分の一」という意味です。
英語の「percent」は、接頭辞「per-」が「~当たり」で、「cent」が「百」なので「百分の一」という意味です。
また、英語の「quant」は「枝分かれしてるもの」という意味になります。
これらに接尾辞「-ile」「~できる」がひっついた形容詞や名詞になって、タイル貼りのように「分割する数値」というニュアンスの言葉になってるのだと思います。
日本語の「分位数」は「順位で分割する数値」という感じで捉えておくと良いと思います。
また、統計系の分野では、「relative」は「相対(そうたい)」と訳しますが「全体に相対(あいたい)する割合(率)」という意味で使われますので、「相対順位」とは「割合(率)の視点で見た順位」のことになります。
表計算ソフトの Excel には四分位数、その他の分位数、相対順位、を計算する関数があります。
バージョンの違いと、定義の違いで何種類かありますので説明します。
Excel ファイルの計算例が(こちら) にありますので、参考にしながら説明を見ると良いでしょう。
Ver.2007以前
Excel のバージョン2007以前には QUARTILE という名前の四分位数を計算する関数と、PERCENTILE という名前のその他の分位数を計算する関数がありました。
また、相対順位(パーセント順位)を計算する PERCENTRANK という関数もありました。
関数 QUARTILE は入力データセットの四分位数が戻ってくる関数です。
次のように使います。
QUARTILE(配列,戻り値)
配列:「データセット」の配列を入力
戻り値:「0」を入力:第0四分位数が戻ってくる
戻り値:「1」を入力:第1四分位数が戻ってくる
戻り値:「2」を入力:第2四分位数が戻ってくる
戻り値:「3」を入力:第3四分位数が戻ってくる
戻り値:「4」を入力:第4四分位数が戻ってくる
関数 PERCENTILE は、入力データセットのある相対順位 $p$ での分位数が戻ってくる関数です。
次のように使います。
PERCENTILE(配列,率)
配列:「データセット」の配列を入力
率:相対順位「$p$」を入力
関数 PERCENTRANK 入力データセットのある数値 x に対する相対順位(パーセント順位)が戻ってくる関数です。
次のように使います。
PERCENTRANK(配列,x,[有効桁数])
配列:「データセット」の配列を入力
x:相対順位を知りたい「数値」を入力
[有効桁数]:省略可能、小数点以下何桁まで計算するかを入力
Ver.2010以降
Excel はバージョンが変わる度に新しい関数が導入されています。
より正確に理解してもらえるようにするために関数名の変更も行われています。
バージョン2007までの関数 QUARTILE と PERCENTILE と PERCENTRANK は、次のバージョン2010で、名前が変更されました。
また、2007には存在しなかった別の定義の関数が2010から新たに導入されました。
名前の関係を表にしました。
ドットの後ろの .INC と .EXC は次のような意味になります。
| .INC | .EXC |
|---|
| inclusive | exclusive |
相対順位範囲に
0 と 1 を含めた定義 | 相対順位範囲で
0 と 1 を除いた定義 |
要は、相対順位と順位の対応に、2種類の定義があると思ってください。
相対順位範囲(パーセントレンジ)に、0 と 1 の端っこが、入るのか入らないのか、ということです。
ただ、これだけでは意味が分からないと思いますので、以下で具体例を交えて説明します。
分位数やパーセンタイルの INC 流の定義は次のものです。
(ii)の順位と相対順位の対応の定義が、後の EXC 流の定義と違います。
- 大きさ順に並べ替えた $n$ 個のデータ $x_i,\, i=1,2,\ldots, n$ を用意する。
\begin{align*}
x_1\lt x_2\lt \cdots \lt x_n
\end{align*}
- 順位 $R$ を、相対順位 $p$ を使って次のように定義する。
\begin{align*}
R=1+\left(n-1\right)p
\end{align*}
$p$ の範囲は、$0\le p\le 1$ になります。
この範囲のことを相対順位範囲といいます。
- $R$ の整数部分を $r$ 、小数部分を $s$ とする。
- $p$ での、分位数(パーセンタイル)$X$ は次のようになる。
\begin{align*}
X=x_r+s\left(x_{r+1}-x_{r}\right)
\end{align*}
この式は変形すると次のようになるので、$x_{r}$ と $x_{r+1}$ の間を $s:(1-s)$ の比に内分する値であることが分かります。
\begin{align*}
X=(1-s)x_r+sx_{r+1}
\end{align*}
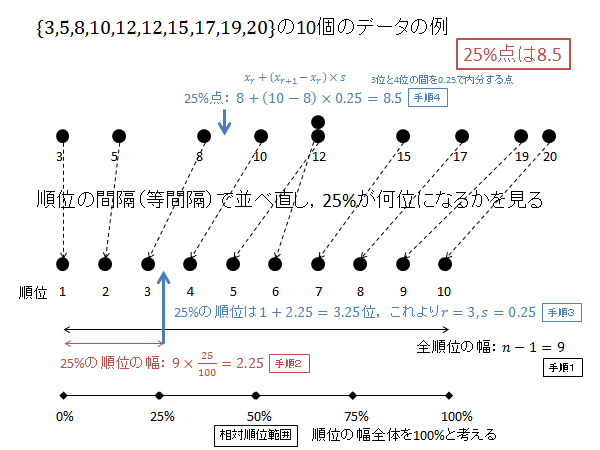
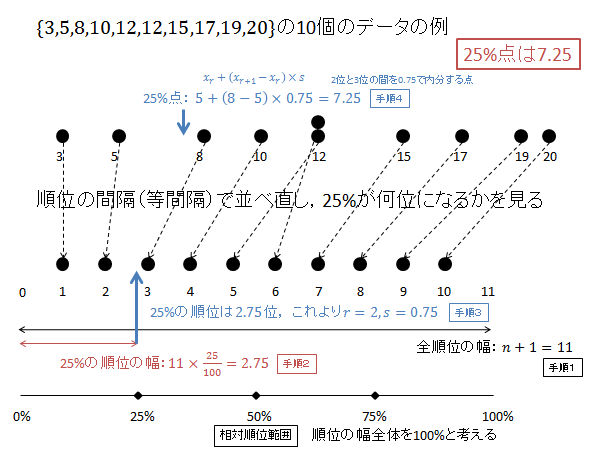
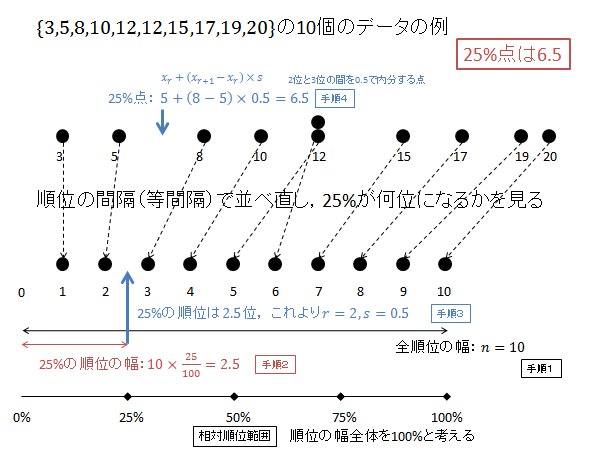
例として、$\{3, 5, 8, 10, 12, 12, 15, 17, 19, 20\}$ の10個のデータの分位数(パーセンタイル)を求めてみましょう。
$n=10$, $x_1=3$, $x_2=5$, $x_3=8$, $x_4=10$, $x_5=12$, $x_6=12$, $x_7=15$, $x_8=17$, $x_9=19$, $x_{10}=20$ です。
第1四分位数(25パーセンタイル)を計算するには次枠のように計算します。
$p=0.25$ の時の $X$ を求めます。
相対順位 25% の順位 $R$ を求めます。(下記図解:手順1、手順2)
\begin{align*}
R=1+\left(10-1\right)\frac{25}{100}=1+9\times\frac{25}{100}=1+2.25=3.25
\end{align*}
$R$ の整数部分 $r$ 、小数部分 $s$ は次のようになります。(下記図解:手順3)
\begin{align*}
r &=3 \\
s &=0.25
\end{align*}
第3位と第4位のデータを $0.25$ で内分する点が25パーセンタイル $X$ になります。(下記図解:手順4)
\begin{align*}
X=x_3+0.25\left(x_4-x_3\right) = 8 + 0.25\left(10-8\right) = 8 + 0.25\times 2 = 8 + 0.5 = 8.5
\end{align*}
以下、上記計算の図解になります。
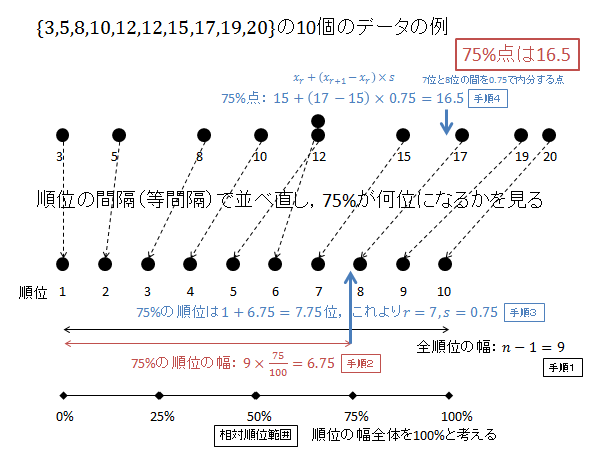
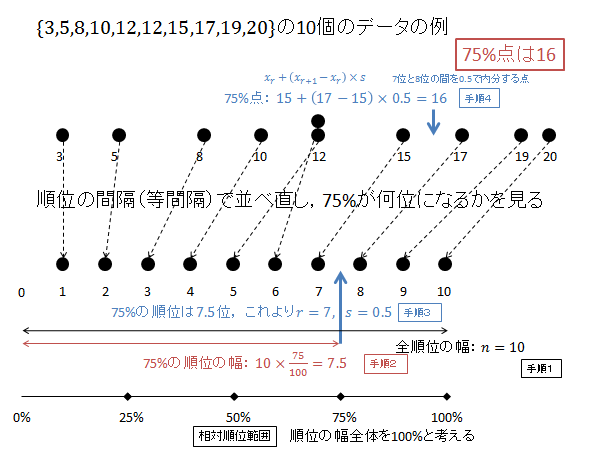
$p=0.75$ の時の $X$ を求めます。
相対順位 75% の順位 $R$ を求めます。(下記図解:手順1、手順2)
\begin{align*}
R=1+\left(10-1\right)\frac{75}{100}=1+9\times\frac{75}{100}=1+6.75=6.75
\end{align*}
$R$ の整数部分 $r$ 、小数部分 $s$ は次のようになります。(下記図解:手順3)
\begin{align*}
r &=6 \\
s &=0.75
\end{align*}
第6位と第7位のデータを $0.75$ で内分する点が75パーセンタイル $X$ になります。(下記図解:手順4)
\begin{align*}
X=x_6+0.75\left(x_7-x_6\right) = 15 + 0.75\left(17-15\right) = 15 + 0.75\times 2 = 15 + 1.5 = 16.5
\end{align*}
以下、上記計算の図解になります。
| データ | 順位 - 1 | 相対順位 | 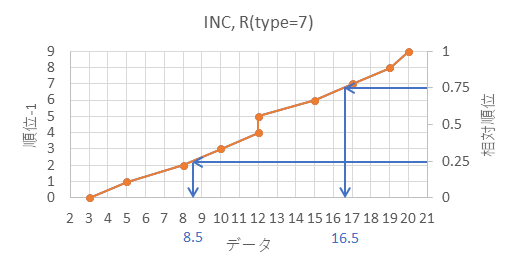 |
|---|
| 3 | 0 | 0/9=0 |
| 5 | 1 | 1/9=0.111111... |
| 8 | 2 | 2/9=0.222222... |
| 10 | 3 | 3/9=0.333333... |
| 12 | 4 | 4/9=0.444444... |
| 12 | 5 | 5/9=0.555555... |
| 15 | 6 | 6/9=0.666666... |
| 17 | 7 | 7/9=0.777777... |
| 19 | 8 | 8/9=0.888888... |
| 20 | 9 | 9/9=1 |
図のように、25%の相対順位に対応するデータの数値が25パーセンタイル、75%の相対順位に対応するデータの数値が75パーセンタイル、になり、他の分位数も綺麗に線を引くことで概算が可能です。
分位数やパーセンタイルの EXC 流の定義は次のものです。
(ii)の順位と相対順位の対応の定義が、前の INC 流の定義と違います。
- 大きさ順に並べ替えた $n$ 個のデータ $x_i,\, i=1,2,\ldots, n$ を用意する。
\begin{align*}
x_1\le x_2\le \cdots \le x_n
\end{align*}
- 順位 $R$ を、相対順位 $p$ を使って次のように定義する。
\begin{align*}
R=\left(n+1\right)p
\end{align*}
$p$ の範囲は、$0\lt p\lt 1$ になります。
この範囲である相対順位範囲に $0$ と $1$ は含まれません。
- $R$ の整数部分を $r$ 、小数部分を $s$ とする。
- 相対順位 $p$ での分位数(パーセンタイル)$X$ は次のようになる。
\begin{align*}
X=x_r+s\left(x_{r+1}-x_{r}\right)
\end{align*}
この式は変形すると次のようになるので、$x_{r}$ と $x_{r+1}$ の間を $s:(1-s)$ の比に内分する値であることが分かります。
\begin{align*}
X=(1-s)x_r+sx_{r+1}
\end{align*}
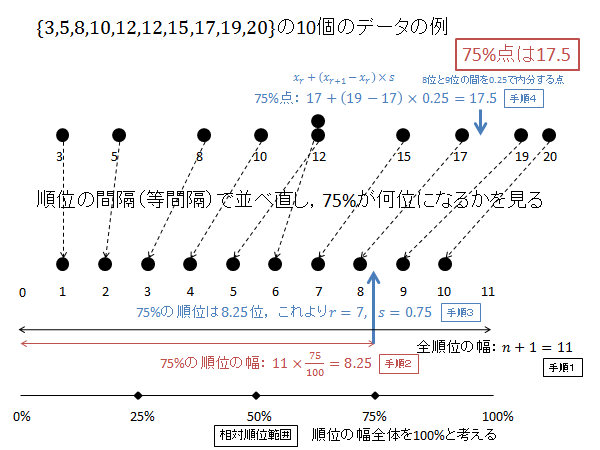
例として、$\{3, 5, 8, 10, 12, 12, 15, 17, 19, 20\}$ の10個のデータの分位数(パーセンタイル)を求めてみましょう。
$n=10$, $x_1=3$, $x_2=5$, $x_3=8$, $x_4=10$, $x_5=12$, $x_6=12$, $x_7=15$, $x_8=17$, $x_9=19$, $x_{10}=20$ です。
第1四分位数(25パーセンタイル)を計算するには次枠のように計算します。
$p=0.25$ の時の $X$ を求めます。
相対順位 25% の順位 $R$ を求めます。(下記図解:手順1、手順2)
\begin{align*}
R=\left(10+1\right)\frac{25}{100}=11\times\frac{25}{100}=2.75
\end{align*}
$R$ の整数部分 $r$ 、小数部分 $s$ は次のようになります。(下記図解:手順3)
\begin{align*}
r &=2 \\
s &=0.75
\end{align*}
第2位と第3位のデータを $0.75$ で内分する点が25パーセンタイル $X$ になります。(下記図解:手順4)
\begin{align*}
X=x_2+0.75\left(x_3-x_2\right) = 5 + 0.75\left(8-5\right) = 5 + 0.75\times 3 = 5 + 2.25 = 7.25
\end{align*}
以下、上記計算の図解になります。
$p=0.75$ の時の $X$ を求めます。
相対順位 75% の順位 $R$ を求めます。(下記図解:手順1、手順2)
\begin{align*}
R=\left(10+1\right)\frac{75}{100}=11\times\frac{75}{100}=8.25
\end{align*}
$R$ の整数部分 $r$ 、小数部分 $s$ は次のようになります。(下記図解:手順3)
\begin{align*}
r &=8 \\
s &=0.25
\end{align*}
第8位と第9位のデータを $0.25$ で内分する点が75パーセンタイル $X$ になります。(下記図解:手順4)
\begin{align*}
X=x_8+0.25\left(x_9-x_8\right) = 17 + 0.25\left(19-17\right) = 17 + 0.25\times 2 = 17 + 0.5 = 17.5
\end{align*}
以下、上記計算の図解になります。
| データ | 順位 | 相対順位 | 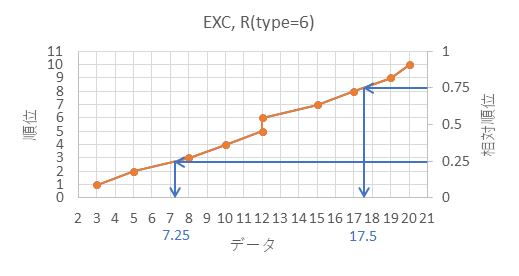 |
|---|
| 3 | 1 | 1/11=0.090909... |
| 5 | 2 | 2/11=0.181818... |
| 8 | 3 | 3/11=0.272727... |
| 10 | 4 | 4/11=0.363636... |
| 12 | 5 | 5/11=0.454545... |
| 12 | 6 | 6/11=0.545454... |
| 15 | 7 | 7/11=0.636363... |
| 17 | 8 | 8/11=0.727272... |
| 19 | 9 | 9/11=0.818181... |
| 20 | 10 | 10/11=0.909090... |
図のように、25%の相対順位に対応するデータの数値が25パーセンタイル、75%の相対順位に対応するデータの数値が75パーセンタイル、になり、他の分位数も綺麗に線を引くことで概算が可能です。
中央値(50パーセンタイル)に関しては、上記2種類のどちらの定義でも必ず同じ値になります。
それは50%相対順位の順位が、どちらの定義でも同じになるからです。
INC 定義では次のようになります。
相対順位 $p=\frac{1}{2}$ での順位 $R$ は次のようになる。
\begin{align*}
R=1+\left(n-1\right)\frac{1}{2}=\frac{n+1}{2}
\end{align*}
EXC 定義では次のようになります。
相対順位 $p=\frac{1}{2}$ での順位 $R$ は次のようになる。
\begin{align*}
R=\left(n+1\right)\frac{1}{2}=\frac{n+1}{2}
\end{align*}
どちらの定義でも $R$ の順位は同じになるので、同じ中央値 $X$ になります。
データ数 $n$ が偶数の時は、$R$ の整数部分 $r$ 、小数部分 $s$ は
\begin{align*}
r &=\frac{n}{2} \\
s &=0.5
\end{align*}
となるので、中央値 $X$ は次のようになります。
\begin{align*}
X = \frac{x_{\frac{n}{2}}+x_{\frac{n}{2}+1}}{2}
\end{align*}
データ数 $n$ が奇数の時は、$R$ の整数部分 $r$ 、小数部分 $s$ は
\begin{align*}
r &=\frac{n+1}{2} \\
s &=0
\end{align*}
となるので、中央値 $X$ は次のようになります。
\begin{align*}
X = x_{\frac{n+1}{2}}
\end{align*}
INC流の定義と、EXC流の定義で特に大きく違うのは、0分位数(0パーセンタイル)、1分位数(100パーセンタイル)の扱いになります。
EXC 流の定義では、相対順位範囲に $0$ と $1$ が含まれていません。
そのため、0分位数も1分位数も存在しません。
.EXC の関数で、0分位数や1分位数を計算すると、「#NUM!」のエラーが返ってきます。
このエラーの説明が(こちら)にあります。
.EXC では 0分位や1分位が存在しないので、それを求めようとすると「無効な数値が入力された」ということになりエラーになります。
最小値と0分位数が同じに、最大値と1分位数が同じになるのは INC 流の定義の方のみです。
EXC 流の定義ではデータ数 $n$ を使って、順位 $R=1$ の時は相対順位 $p=\frac{1}{n+1}$に、順位 $R=n$ の時は相対順位 $p=\frac{n}{n+1}$ です。
まとめると次のようになります。
| .INC | .EXC |
|---|
| 0分位数 | 最小値 | 存在しない |
|---|
| $\frac{1}{n+1}$分位数 | 特に意味のない値 | 最小値 |
|---|
| $\frac{n}{n+1}$分位数 | 特に意味のない値 | 最大値 |
|---|
| 1分位数 | 最大値 | 存在しない |
|---|
分位数を求めるには何種類もの流儀がありますが、どれを使うべきか、ということに特に決まりはありません。
INC 流の定義は、最小値・最大値と0分位・1分位の対応がついているところが良いところだと思います。
EXC 流の定義は、順位と相対順位の対応計算が比較的簡単な式なのが良いところだと思います。
データ数 $n$ が大きくなると、データ間の相対順位の間隔がどんどん狭くなっていきます。
最大値・最小値、以外の分位数の値は、どちらの定義でも殆ど同じ値になります。
データ数 $n$ が小さい時、定義による違いは目立ってきます。
そのような場合は、どちらの定義に基づいて計算しているのか、明示しておく必要があります。
2種類の定義の違いは、順位という自然数と、相対順位という実数(有限のデータ数では有理数)を、対応付ける際に出てきたものです。
数学的に全く性質の違う自然数と実数を、無理やり対応付けたために、このようなことになってしまったのだと考えてください。
分位数自体は、データの分布を分析する際に非常に有用な考え方なので、2種類の違いは知っておいた上で、あまり気にせずに使用していくのが良いと思います。
「連続データ」ではデータを範囲に区切った「階級」というものを使って分布を要約します。
分位数を求める際には、「相対順位」に対応する「累積相対度数」というものを使います。
(こちらの講義)で累積相対度数を利用した分位数(パーセント点)の求め方を説明していますので、参考にしてください。
Excel は表計算を主な目的としたアプリで、統計分析用の便利な関数もたくさん用意されています。
世の中には Excel 以外にも、統計処理の機能が充実したアプリや、数式処理の機能が充実したアプリが存在します。
分位数を求める関数も豊富で、Excelの2種類のタイプの流儀以外にも、様々なタイプの流儀が存在します。
R というアプリは、統計処理の総合環境を目的としたアプリです。
標準で stat というパッケージが入っていまして、その中に quantile という名前の関数があります。
この関数には、type というオプション(属性)があり、この type に 1~9 までの数値を指定することで、9つのタイプの分位数を使い分けることができます。
それぞれに、微妙な違いがあるのですが、必要になった時のために違いを知っておくと良いでしょう。
ちなみに、type=7 は Excel の INC 流、type=6 は Excel の EXC 流、に対応します。
R 以外にも、SAS, Stata, Python, Julia, Maple 等々の様々なアプリや言語がありますが、それぞれどのようなものがあるのか、(こちら)の対応表が参考になります。
R をインストールして、コンソール画面に、次の赤字のように x にデータセットを指定し、prob に知りたい分位数の相対順位を指定します。
更に、type=7 のオプションを指定すると、青字の答えが返ってきます。
上の例の INC 流の定義と同じ答えです。
ちなみに、type オプションを省略した時のデフォルトの設定は、type=7 とみなされます。
> quantile(x=c(3,5,8,10,12,12,15,17,19,20),probs=c(0,0.25,0.50,0.75,1),type=7)
0% 25% 50% 75% 100%
3.00 7.25 12.00 17.50 20.00
次の赤字のように type=6 のオプションを指定すると、青字の答えが返ってきます。
0% は最小値に、100% は最大値になりますが、その他の分位数は上の例の EXC 流の定義と同じ答えです。
Excel と違って、$\frac{1}{n+1}$分位数以下は最小値、$\frac{n}{n+1}$分位数以上は最大値、になるように補正を行っていますが、それ以外は Excel 関数と同じ答えになります。
> quantile(x=c(3,5,8,10,12,12,15,17,19,20),probs=c(0,0.25,0.50,0.75,1),type=6)
0% 25% 50% 75% 100%
3.0 8.5 12.0 16.5 20.0
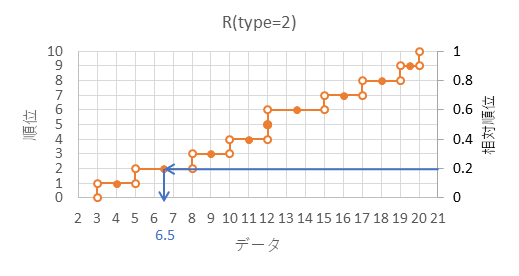
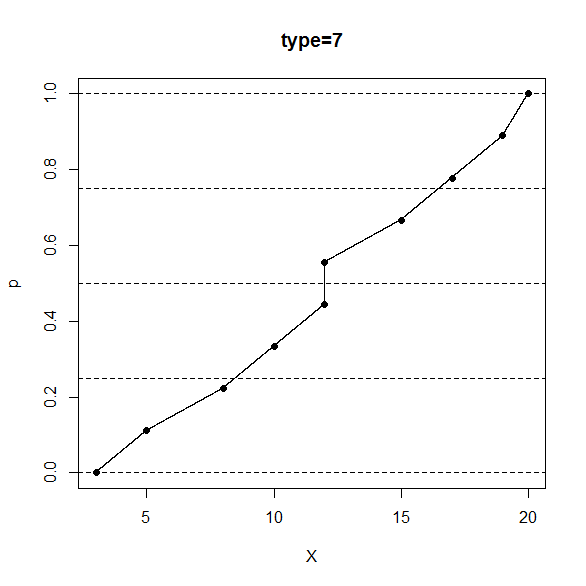
ちなみに、R のコンソール画面で、次のように打ち込むと、type=7 の定義の分位数と相対順位の対応関係が分かります。
> data <- sort(c(3,5,8,10,12,12,15,17,19,20))
> p <- seq(from=0,to=1,by=0.0001)
> X <- quantile(x=data,probs=p,type=7)
> plot(x=X,y=p,pch=".",main="type=7")
> n <- length(data)
> pd <- (seq_along(data)-1)/(n-1)
> Xd <- quantile(x=data,probs=pd,type=7)
> points(x=Xd,y=pd,pch=16)
> abline(h=c(0,0.25,0.5,0.75,1),lty=2)
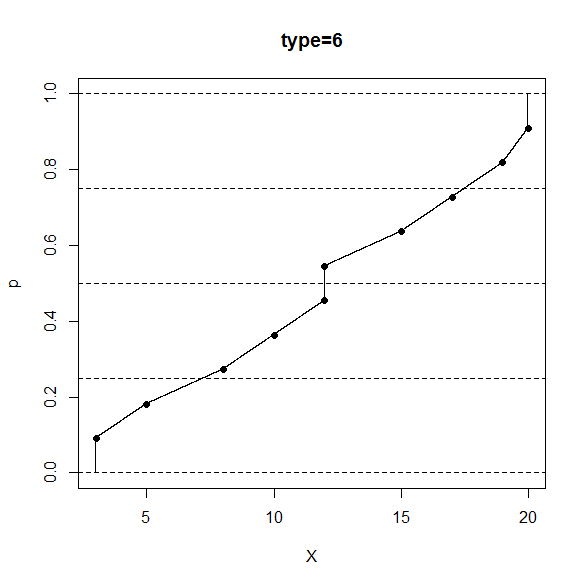
R のコンソール画面で、次のように打ち込むと、type=6 の定義の分位数と相対順位の対応関係が分かります。
> data <- sort(c(3,5,8,10,12,12,15,17,19,20))
> p <- seq(from=0,to=1,by=0.0001)
> X <- quantile(x=data,probs=p,type=6)
> plot(x=X,y=p,pch=".",main="type=6")
> n <- length(data)
> pd <- seq_along(data)/(n+1)
> Xd <- quantile(x=data,probs=pd,type=6)
> points(x=Xd,y=pd,pch=16)
> abline(h=c(0,0.25,0.5,0.75,1),lty=2)
この流儀は、EXC 流の定義の、exclude 具合(はみ出し具合)を変えたものになります。
type=6 では両側に 1 順位はみ出ていたのですが、この type=5では両側に 1/2 順位はみ出た定義になっています。
この定義は、全順位の幅がデータ数 $n$ であるところが、分かりやすくて良いところだと思います。
分位数やパーセンタイルの type=5 流の定義は次のものです。
(ii)の順位と相対順位の対応の定義が、前の type=6,7 流の定義と違います。
- 大きさ順に並べ替えた $n$ 個のデータ $x_i,\, i=1,2,\ldots, n$ を用意する。
\begin{align*}
x_1\le x_2\le \cdots \le x_n
\end{align*}
- 順位 $R$ を、相対順位 $p$ を使って次のように定義する。
\begin{align*}
R=\frac{1}{2}+np
\end{align*}
$p$ の範囲は、$0\lt p\lt 1$ になります。
この範囲である相対順位範囲に $0$ と $1$ は含まれません。
- $R$ の整数部分を $r$ 、小数部分を $s$ とする。
- 相対順位 $p$ での分位数(パーセンタイル)$X$ は次のようになる。
\begin{align*}
X=x_r+s\left(x_{r+1}-x_{r}\right)
\end{align*}
例として、$\{3, 5, 8, 10, 12, 12, 15, 17, 19, 20\}$ の10個のデータの分位数(パーセンタイル)を求めてみましょう。
$n=10$, $x_1=3$, $x_2=5$, $x_3=8$, $x_4=10$, $x_5=12$, $x_6=12$, $x_7=15$, $x_8=17$, $x_9=19$, $x_{10}=20$ です。
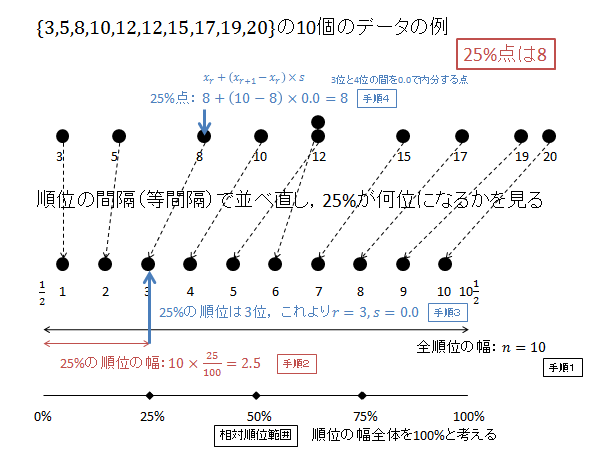
第1四分位数(25パーセンタイル)を計算するには次枠のように計算します。
$p=0.25$ の時の $X$ を求めます。
相対順位 25% の順位 $R$ を求めます。(下記図解:手順1、手順2)
\begin{align*}
R=\frac{1}{2}+10\times\frac{25}{100}=0.5+2.5=3
\end{align*}
$R$ の整数部分 $r$ 、小数部分 $s$ は次のようになります。(下記図解:手順3)
\begin{align*}
r &=3 \\
s &=0.0
\end{align*}
第3位と第4位のデータを $0.0$ で内分する点が25パーセンタイル $X$ になります。(下記図解:手順4)
\begin{align*}
X=x_3+0.0\left(x_4-x_3\right) = 8 + 0.0\left(10-8\right) = 8 + 0.0 = 8
\end{align*}
以下、上記計算の図解になります。
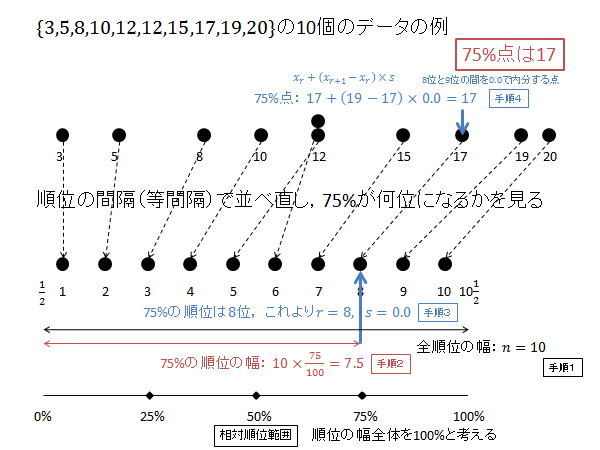
$p=0.75$ の時の $X$ を求めます。
相対順位 75% の順位 $R$ を求めます。(下記図解:手順1、手順2)
\begin{align*}
R=\frac{1}{2}+10\times\frac{75}{100}=0.5+7.5=8
\end{align*}
$R$ の整数部分 $r$ 、小数部分 $s$ は次のようになります。(下記図解:手順3)
\begin{align*}
r &=8 \\
s &=0.0
\end{align*}
第8位と第9位のデータを $0.0$ で内分する点が75パーセンタイル $X$ になります。(下記図解:手順4)
\begin{align*}
X=x_8+0.0\left(x_9-x_8\right) = 17 + 0.0\left(19-17\right) = 17 + 0.0 = 17
\end{align*}
以下、上記計算の図解になります。
| データ | 順位-1/2 | 相対順位 | 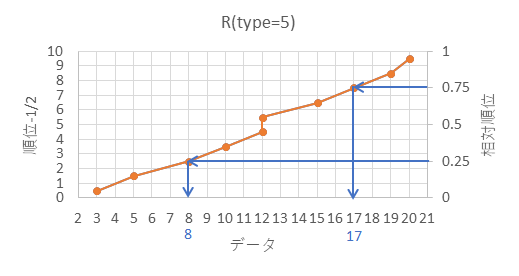 |
|---|
| 3 | 0.5 | 0.5/10=0.05 |
| 5 | 1.5 | 1.5/10=0.15 |
| 8 | 2.5 | 2.5/10=0.25 |
| 10 | 3.5 | 3.5/10=0.35 |
| 12 | 4.5 | 4.5/10=0.45 |
| 12 | 5.5 | 5.5/10=0.55 |
| 15 | 6.5 | 6.5/10=0.65 |
| 17 | 7.5 | 7.5/10=0.75 |
| 19 | 8.5 | 8.5/10=0.85 |
| 20 | 9.5 | 9.5/10=0.95 |
図のように、25%の相対順位に対応するデータの数値が25パーセンタイル、75%の相対順位に対応するデータの数値が75パーセンタイル、になり、他の分位数も綺麗に線を引くことで概算が可能です。
R のコンソール画面で、次の赤字のように x にデータセットを指定し、prob に知りたい分位数の相対順位を指定します。
更に、type=5 のオプションを指定すると、青字の答えが返ってきます。
0% は最小値に、100% は最大値になりますが、$\frac{1}{2n}$分位数以下は最小値、$\frac{2n-1}{2n}$分位数以上は最大値、になるように補正を行っているからです。
> quantile(x=c(3,5,8,10,12,12,15,17,19,20),probs=c(0,0.25,0.50,0.75,1),type=5)
0% 25% 50% 75% 100%
3 8 12 17 20
R のコンソール画面で、次のように打ち込むと、type=5 の定義の分位数と相対順位の対応関係が分かります。
> data <- sort(c(3,5,8,10,12,12,15,17,19,20))
> p <- seq(from=0,to=1,by=0.0001)
> X <- quantile(x=data,probs=p,type=5)
> plot(x=X,y=p,pch=".",main="type=5")
> n <- length(data)
> pd <- (seq_along(data)-1/2)/n
> Xd <- quantile(x=data,probs=pd,type=5)
> points(x=Xd,y=pd,pch=16)
> abline(h=c(0,0.25,0.5,0.75,1),lty=2)
この流儀は、EXC 流の定義の、exclude 具合(はみ出し具合)を変えたものになります。
type=6 では両側に 1 順位はみ出ていたのですが、この type=5では両側に 2/3 順位はみ出た定義になっています。
分位数やパーセンタイルの type=8 流の定義は次のものです。
(ii)の順位と相対順位の対応の定義が、前の type=5,6,7 流の定義と違います。
- 大きさ順に並べ替えた $n$ 個のデータ $x_i,\, i=1,2,\ldots, n$ を用意する。
\begin{align*}
x_1\le x_2\le \cdots \le x_n
\end{align*}
- 順位 $R$ を、相対順位 $p$ を使って次のように定義する。
\begin{align*}
R=\frac{1}{3}+\left(n+\frac{1}{3}\right)p
\end{align*}
$p$ の範囲は、$0\lt p\lt 1$ になります。
この範囲である相対順位範囲に $0$ と $1$ は含まれません。
- $R$ の整数部分を $r$ 、小数部分を $s$ とする。
- 相対順位 $p$ での分位数(パーセンタイル)$X$ は次のようになる。
\begin{align*}
X=x_r+s\left(x_{r+1}-x_{r}\right)
\end{align*}
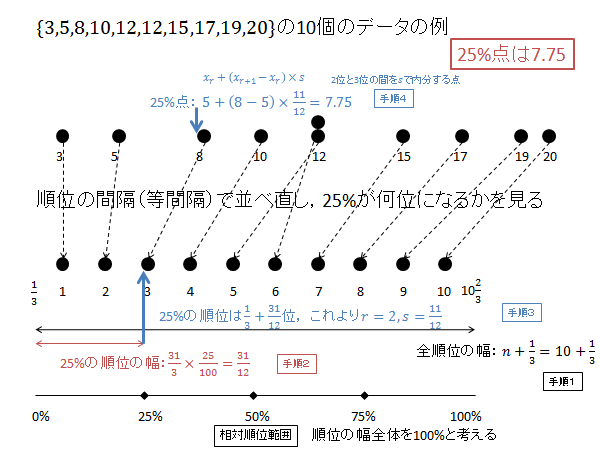
例として、$\{3, 5, 8, 10, 12, 12, 15, 17, 19, 20\}$ の10個のデータの分位数(パーセンタイル)を求めてみましょう。
$n=10$, $x_1=3$, $x_2=5$, $x_3=8$, $x_4=10$, $x_5=12$, $x_6=12$, $x_7=15$, $x_8=17$, $x_9=19$, $x_{10}=20$ です。
第1四分位数(25パーセンタイル)を計算するには次枠のように計算します。
$p=0.25$ の時の $X$ を求めます。
相対順位 25% の順位 $R$ を求めます。(下記図解:手順1、手順2)
\begin{align*}
R=\frac{1}{3}+\left(10+\frac{1}{3}\right)\times\frac{25}{100}=\frac{1}{3}+\frac{31}{12}=\frac{35}{12}=2.91\dot{6}
\end{align*}
$R$ の整数部分 $r$ 、小数部分 $s$ は次のようになります。(下記図解:手順3)
\begin{align*}
r &=2 \\
s &=\frac{35}{12}-2=\frac{11}{12}
\end{align*}
第2位と第3位のデータを $s$ で内分する点が25パーセンタイル $X$ になります。(下記図解:手順4)
\begin{align*}
X=x_2+\frac{11}{12}\left(x_3-x_2\right) = 5 + \frac{11}{12}\left(8-5\right) = 5 + \frac{11}{4} = 7.75
\end{align*}
以下、上記計算の図解になります。
$p=0.75$ の時の $X$ を求めます。
相対順位 75% の順位 $R$ を求めます。(下記図解:手順1、手順2)
\begin{align*}
R=\frac{1}{3}+\left(10+\frac{1}{3}\right)\times\frac{75}{100}=\frac{1}{3}+\frac{31}{4}=\frac{97}{12}=8.08\dot{3}
\end{align*}
$R$ の整数部分 $r$ 、小数部分 $s$ は次のようになります。(下記図解:手順3)
\begin{align*}
r &=8 \\
s &=\frac{97}{12}-8=\frac{1}{12}
\end{align*}
第8位と第9位のデータを $s$ で内分する点が75パーセンタイル $X$ になります。(下記図解:手順4)
\begin{align*}
X=x_8+\frac{1}{12}\left(x_9-x_8\right) = 17 + \frac{1}{12}\left(19-17\right) = 17 + \frac{1}{6} = 17.1\dot{6}
\end{align*}
以下、上記計算の図解になります。

| データ | 順位-1/3 | 相対順位 | 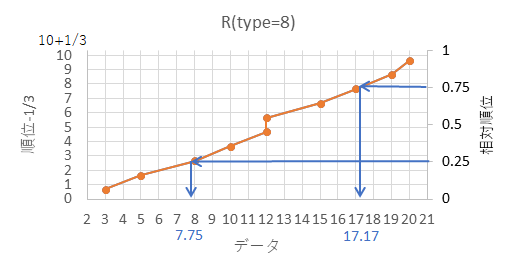 |
|---|
| 3 | 0.666666... | (1-1/3)/(10+1/3)=0.064516... |
| 5 | 1.666666... | (2-1/3)/(10+1/3)=0.161290... |
| 8 | 2.666666... | (3-1/3)/(10+1/3)=0.258064... |
| 10 | 3.666666... | (4-1/3)/(10+1/3)=0.354838... |
| 12 | 4.666666... | (5-1/3)/(10+1/3)=0.451612... |
| 12 | 5.666666... | (6-1/3)/(10+1/3)=0.548387... |
| 15 | 6.666666... | (7-1/3)/(10+1/3)=0.645161... |
| 17 | 7.666666... | (8-1/3)/(10+1/3)=0.741935... |
| 19 | 8.666666... | (9-1/3)/(10+1/3)=0.838709... |
| 20 | 9.666666... | (10-1/3)/(10+1/3)=0.935483... |
図のように、25%の相対順位に対応するデータの数値が25パーセンタイル、75%の相対順位に対応するデータの数値が75パーセンタイル、になり、他の分位数も綺麗に線を引くことで概算が可能です。
R のコンソール画面で、次の赤字のように x にデータセットを指定し、prob に知りたい分位数の相対順位を指定します。
更に、type=8 のオプションを指定すると、青字の答えが返ってきます。
0% は最小値に、100% は最大値になりますが、$\frac{2}{3n+1}$分位数以下は最小値、$\frac{3n-1}{3n+1}$分位数以上は最大値、になるように補正を行っているからです。
> quantile(x=c(3,5,8,10,12,12,15,17,19,20),probs=c(0,0.25,0.50,0.75,1),type=8)
0% 25% 50% 75% 100%
3.00000 7.75000 12.00000 17.16667 20.00000
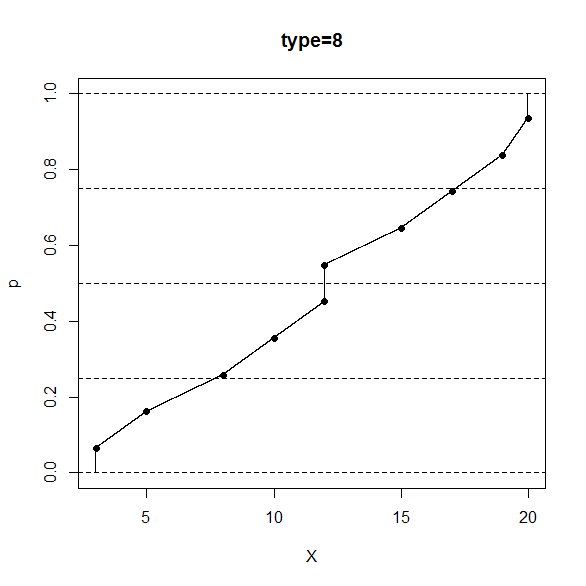
R のコンソール画面で、次のように打ち込むと、type=8 の定義の分位数と相対順位の対応関係が分かります。
> data <- sort(c(3,5,8,10,12,12,15,17,19,20))
> p <- seq(from=0,to=1,by=0.0001)
> X <- quantile(x=data,probs=p,type=8)
> plot(x=X,y=p,pch=".",main="type=8")
> n <- length(data)
> pd <- (seq_along(data)-1/3)/(n+1/3)
> Xd <- quantile(x=data,probs=pd,type=8)
> points(x=Xd,y=pd,pch=16)
> abline(h=c(0,0.25,0.5,0.75,1),lty=2)
この流儀は、EXC 流の定義の、exclude 具合(はみ出し具合)を変えたものになります。
type=6 では両側に 1 順位はみ出ていたのですが、この type=5では両側に 5/8 順位はみ出た定義になっています。
分位数やパーセンタイルの type=9 流の定義は次のものです。
(ii)の順位と相対順位の対応の定義が、前の type=5,6,7,8 流の定義と違います。
- 大きさ順に並べ替えた $n$ 個のデータ $x_i,\, i=1,2,\ldots, n$ を用意する。
\begin{align*}
x_1\le x_2\le \cdots \le x_n
\end{align*}
- 順位 $R$ を、相対順位 $p$ を使って次のように定義する。
\begin{align*}
R=\frac{3}{8}+\left(n+\frac{1}{4}\right)p
\end{align*}
$p$ の範囲は、$0\lt p\lt 1$ になります。
この範囲である相対順位範囲に $0$ と $1$ は含まれません。
- $R$ の整数部分を $r$ 、小数部分を $s$ とする。
- 相対順位 $p$ での分位数(パーセンタイル)$X$ は次のようになる。
\begin{align*}
X=x_r+s\left(x_{r+1}-x_{r}\right)
\end{align*}
例として、$\{3, 5, 8, 10, 12, 12, 15, 17, 19, 20\}$ の10個のデータの分位数(パーセンタイル)を求めてみましょう。
$n=10$, $x_1=3$, $x_2=5$, $x_3=8$, $x_4=10$, $x_5=12$, $x_6=12$, $x_7=15$, $x_8=17$, $x_9=19$, $x_{10}=20$ です。
第1四分位数(25パーセンタイル)を計算するには次枠のように計算します。
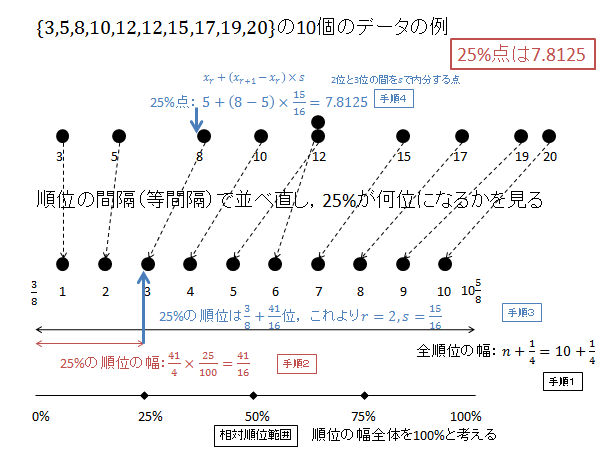
$p=0.25$ の時の $X$ を求めます。
相対順位 25% の順位 $R$ を求めます。(下記図解:手順1、手順2)
\begin{align*}
R=\frac{3}{8}+\left(10+\frac{1}{4}\right)\times\frac{25}{100}=\frac{3}{8}+\frac{41}{16}=\frac{47}{16}=2.9375
\end{align*}
$R$ の整数部分 $r$ 、小数部分 $s$ は次のようになります。(下記図解:手順3)
\begin{align*}
r &=2 \\
s &=\frac{47}{16}-2=\frac{15}{16}
\end{align*}
第2位と第3位のデータを $s$ で内分する点が25パーセンタイル $X$ になります。(下記図解:手順4)
\begin{align*}
X=x_2+\frac{11}{12}\left(x_3-x_2\right) = 5 + \frac{15}{16}\left(8-5\right) = 5 + \frac{45}{16} = 7.8125
\end{align*}
以下、上記計算の図解になります。
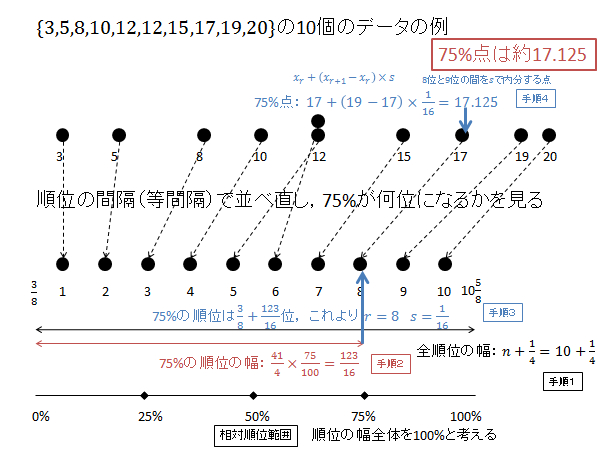
$p=0.75$ の時の $X$ を求めます。
相対順位 75% の順位 $R$ を求めます。(下記図解:手順1、手順2)
\begin{align*}
R=\frac{3}{8}+\left(10+\frac{1}{4}\right)\times\frac{75}{100}=\frac{3}{8}+\frac{123}{16}=\frac{129}{16}=8.0625
\end{align*}
$R$ の整数部分 $r$ 、小数部分 $s$ は次のようになります。(下記図解:手順3)
\begin{align*}
r &=8 \\
s &=\frac{129}{16}-8=\frac{1}{16}
\end{align*}
第8位と第9位のデータを $s$ で内分する点が75パーセンタイル $X$ になります。(下記図解:手順4)
\begin{align*}
X=x_8+\frac{1}{12}\left(x_9-x_8\right) = 17 + \frac{1}{16}\left(19-17\right) = 17 + \frac{1}{8} = 17.125
\end{align*}
以下、上記計算の図解になります。
| データ | 順位-3/8 | 相対順位 | 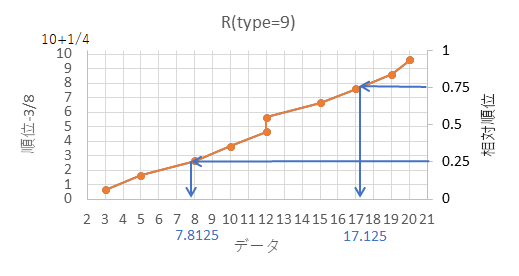 |
|---|
| 3 | 0.625 | (1-3/8)/(10+1/4)=0.060975... |
| 5 | 1.625 | (2-3/8)/(10+1/4)=0.158536... |
| 8 | 2.625 | (3-3/8)/(10+1/4)=0.256097... |
| 10 | 3.625 | (4-3/8)/(10+1/4)=0.353658... |
| 12 | 4.625 | (5-3/8)/(10+1/4)=0.451219... |
| 12 | 5.625 | (6-3/8)/(10+1/4)=0.548780... |
| 15 | 6.625 | (7-3/8)/(10+1/4)=0.646341... |
| 17 | 7.625 | (8-3/8)/(10+1/4)=0.743902... |
| 19 | 8.625 | (9-3/8)/(10+1/4)=0.841463... |
| 20 | 9.725 | (10-3/8)/(10+1/4)=0.993902... |
図のように、25%の相対順位に対応するデータの数値が25パーセンタイル、75%の相対順位に対応するデータの数値が75パーセンタイル、になり、他の分位数も綺麗に線を引くことで概算が可能です。
R のコンソール画面で、次の赤字のように x にデータセットを指定し、prob に知りたい分位数の相対順位を指定します。
更に、type=9 のオプションを指定すると、青字の答えが返ってきます。
0% は最小値に、100% は最大値になりますが、$\frac{3}{4n+1}$分位数以下は最小値、$\frac{4n-1}{4n+1}$分位数以上は最大値、になるように補正を行っているからです。
> quantile(x=c(3,5,8,10,12,12,15,17,19,20),probs=c(0,0.25,0.50,0.75,1),type=9)
0% 25% 50% 75% 100%
3.0000 7.8125 12.0000 17.1250 20.0000
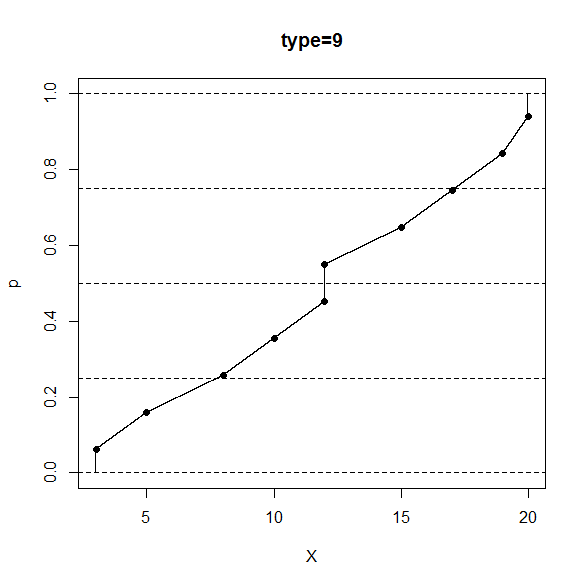
R のコンソール画面で、次のように打ち込むと、type=9 の定義の分位数と相対順位の対応関係が分かります。
> data <- sort(c(3,5,8,10,12,12,15,17,19,20))
> p <- seq(from=0,to=1,by=0.0001)
> X <- quantile(x=data,probs=p,type=9)
> plot(x=X,y=p,pch=".",main="type=9")
> n <- length(data)
> pd <- (seq_along(data)-3/8)/(n+1/4)
> Xd <- quantile(x=data,probs=pd,type=9)
> points(x=Xd,y=pd,pch=16)
> abline(h=c(0,0.25,0.5,0.75,1),lty=2)
この type=4 では左側に 1 順位はみ出て、右側にははみ出ていない、非対称なはみ出し具合になります。
順位と相対順位の対応が非常に簡単なのが良いところです。
分位数やパーセンタイルの type=4 流の定義は次のものです。
(ii)の順位と相対順位の対応の定義が、前の type=5,6,7,8,9 流の定義と違います。
- 大きさ順に並べ替えた $n$ 個のデータ $x_i,\, i=1,2,\ldots, n$ を用意する。
\begin{align*}
x_1\le x_2\le \cdots \le x_n
\end{align*}
- 順位 $R$ を、相対順位 $p$ を使って次のように定義する。
\begin{align*}
R=np
\end{align*}
$p$ の範囲は、$0\lt p\le 1$ になります。
この範囲である相対順位範囲に $0$ は含まれません。
- $R$ の整数部分を $r$ 、小数部分を $s$ とする。
- 相対順位 $p$ での分位数(パーセンタイル)$X$ は次のようになる。
\begin{align*}
X=x_r+s\left(x_{r+1}-x_{r}\right)
\end{align*}
例として、$\{3, 5, 8, 10, 12, 12, 15, 17, 19, 20\}$ の10個のデータの分位数(パーセンタイル)を求めてみましょう。
$n=10$, $x_1=3$, $x_2=5$, $x_3=8$, $x_4=10$, $x_5=12$, $x_6=12$, $x_7=15$, $x_8=17$, $x_9=19$, $x_{10}=20$ です。
第1四分位数(25パーセンタイル)を計算するには次枠のように計算します。
$p=0.25$ の時の $X$ を求めます。
相対順位 25% の順位 $R$ を求めます。(下記図解:手順1、手順2)
\begin{align*}
R=10\times 0.25=2.5
\end{align*}
$R$ の整数部分 $r$ 、小数部分 $s$ は次のようになります。(下記図解:手順3)
\begin{align*}
r &=2 \\
s &=0.5
\end{align*}
第2位と第3位のデータを $0.5$ で内分する点が25パーセンタイル $X$ になります。(下記図解:手順4)
\begin{align*}
X=x_2+0.5\left(x_3-x_2\right) = 5 + 0.5\left(8-5\right) = 5 + 1.5 = 7.5
\end{align*}
以下、上記計算の図解になります。
$p=0.75$ の時の $X$ を求めます。
相対順位 75% の順位 $R$ を求めます。(下記図解:手順1、手順2)
\begin{align*}
R=10\times 0.75=7.5
\end{align*}
$R$ の整数部分 $r$ 、小数部分 $s$ は次のようになります。(下記図解:手順3)
\begin{align*}
r &=7 \\
s &=0.5
\end{align*}
第7位と第8位のデータを $0.5$ で内分する点が75パーセンタイル $X$ になります。(下記図解:手順4)
\begin{align*}
X=x_7+0.5\left(x_8-x_7\right) = 15 + 0.5\left(17-15\right) = 15 + 1 = 16
\end{align*}
以下、上記計算の図解になります。
| データ | 順位 | 相対順位 | 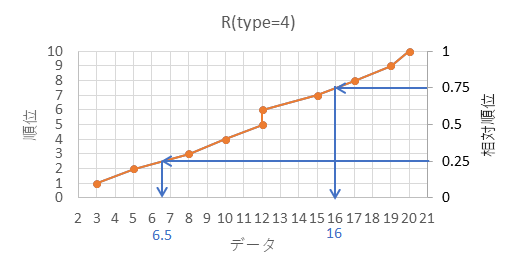 |
|---|
| 3 | 1 | 1/10=0.1 |
| 5 | 2 | 2/10=0.2 |
| 8 | 3 | 3/10=0.3 |
| 10 | 4 | 4/10=0.4 |
| 12 | 5 | 5/10=0.5 |
| 12 | 6 | 6/10=0.6 |
| 15 | 7 | 7/10=0.7 |
| 17 | 8 | 8/10=0.8 |
| 19 | 9 | 9/10=0.9 |
| 20 | 10 | 10/10=1.0 |
図のように、25%の相対順位に対応するデータの数値が25パーセンタイル、75%の相対順位に対応するデータの数値が75パーセンタイル、になり、他の分位数も綺麗に線を引くことで概算が可能です。
R のコンソール画面で、次の赤字のように x にデータセットを指定し、prob に知りたい分位数の相対順位を指定します。
更に、type=4 のオプションを指定すると、青字の答えが返ってきます。
0% は最小値になりますが、$\frac{1}{n}$分位数以下は最小値になるように補正を行っているからです。
> quantile(x=c(3,5,8,10,12,12,15,17,19,20),probs=c(0,0.25,0.50,0.75,1),type=4)
0% 25% 50% 75% 100%
3.0 6.5 12.0 16.0 20.0
R のコンソール画面で、次のように打ち込むと、type=4 の定義の分位数と相対順位の対応関係が分かります。
> data <- sort(c(3,5,8,10,12,12,15,17,19,20))
> p <- seq(from=0,to=1,by=0.0001)
> X <- quantile(x=data,probs=p,type=4)
> plot(x=X,y=p,pch=".",main="type=4")
> n <- length(data)
> pd <- seq_along(data)/n
> Xd <- quantile(x=data,probs=pd,type=4)
> points(x=Xd,y=pd,pch=16)
> abline(h=c(0,0.25,0.5,0.75,1),lty=2)
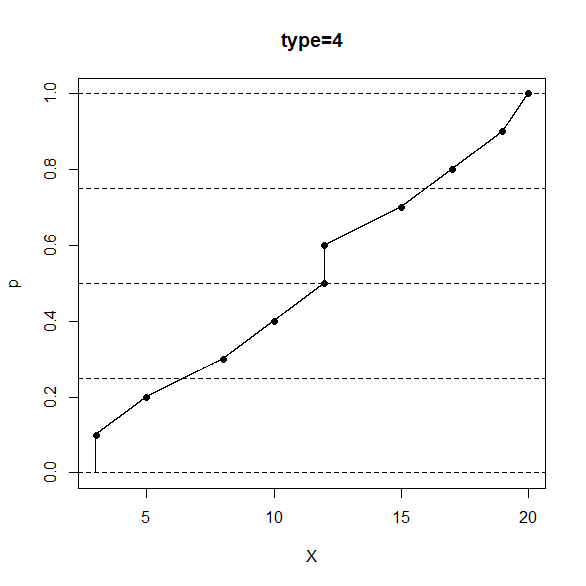
この定義は、はみ出し方が非対称なので、中央値(50パーセンタイル)がこれまでの定義とは違うものになるのが注意点です。
相対順位 $p=\frac{1}{2}$ での順位 $R$ は次のようになる。
\begin{align*}
R=\frac{n}{2}
\end{align*}
データ数 $n$ が偶数の時は、$R$ の整数部分 $r$ 、小数部分 $s$ は
\begin{align*}
r &=\frac{n}{2} \\
s &=0.0
\end{align*}
となるので、中央値 $X$ は次のようになります。
\begin{align*}
X = x_{\frac{n}{2}}
\end{align*}
データ数 $n$ が奇数の時は、$R$ の整数部分 $r$ 、小数部分 $s$ は
\begin{align*}
r &=\frac{n-1}{2} \\
s &=0.5
\end{align*}
となるので、中央値 $X$ は次のようになります。
\begin{align*}
X = \frac{x_{\frac{n-1}{2}}+x_{\frac{n+1}{2}}}{2}
\end{align*}
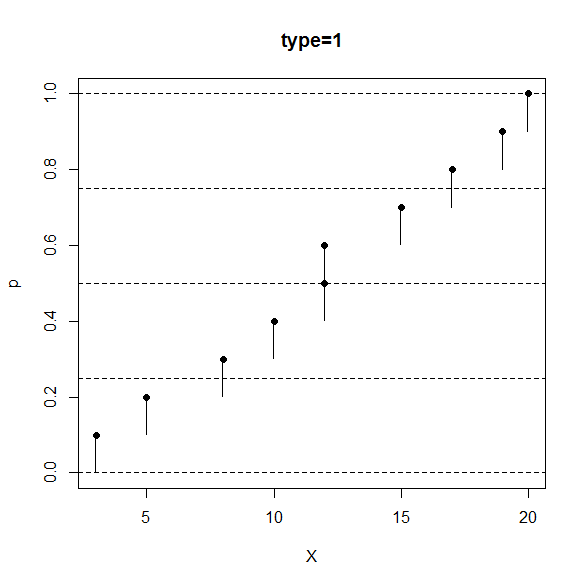
この type=1 は順位と相対順位の対応は、前の type=4 と同じです。
小数順位の扱いが違いまして、type=4 では内分点を使ったのに対して、type=1 では切り上げを用います。
実はこの type=1 の流儀は、一番計算手順が簡単で、自作のプログラミングも簡単です。
データ数が大量の場合での計算も速いので、最も良く使われているのではないかと思われます。
分位数やパーセンタイルの type=1 流の定義は次のものです。
(i)(ii)の順位と相対順位の対応は、前の type=4 流の定義と同じで、(iii)(iv) の定義が違います。
- 大きさ順に並べ替えた $n$ 個のデータ $x_i,\, i=1,2,\ldots, n$ を用意する。
\begin{align*}
x_1\le x_2\le \cdots \le x_n
\end{align*}
- 順位 $R$ を、相対順位 $p$ を使って次のように定義する。
\begin{align*}
R=np
\end{align*}
$p$ の範囲は、$0\lt p\le 1$ になります。
この範囲である相対順位範囲に $0$ は含まれません。
- $R$ の小数部分を切り上げた値を $t$ とする。
- 相対順位 $p$ での分位数(パーセンタイル)$X$ は次のようになる。
\begin{align*}
X=x_t
\end{align*}
例として、$\{3, 5, 8, 10, 12, 12, 15, 17, 19, 20\}$ の10個のデータの分位数(パーセンタイル)を求めてみましょう。
$n=10$, $x_1=3$, $x_2=5$, $x_3=8$, $x_4=10$, $x_5=12$, $x_6=12$, $x_7=15$, $x_8=17$, $x_9=19$, $x_{10}=20$ です。
第1四分位数(25パーセンタイル)を計算するには次枠のように計算します。
$p=0.25$ の時の $X$ を求めます。
相対順位 25% の順位 $R$ を求めます。(下記図解:手順1、手順2)
\begin{align*}
R=10\times 0.25=2.5
\end{align*}
$R$ の小数部分を切り上げた順位 $t$ は次のようになります。(下記図解:手順3)
\begin{align*}
t &=3
\end{align*}
第3位のデータが25パーセンタイル $X$ になります。(下記図解:手順4)
\begin{align*}
X=x_3 = 8
\end{align*}
以下、上記計算の図解になります。
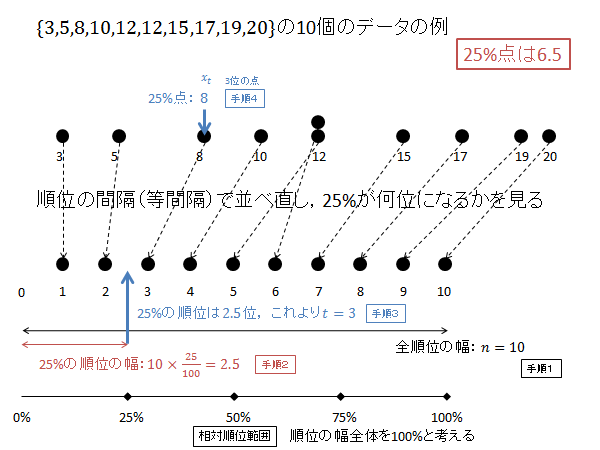
$p=0.75$ の時の $X$ を求めます。
相対順位 75% の順位 $R$ を求めます。(下記図解:手順1、手順2)
\begin{align*}
R=10\times 0.75=7.5
\end{align*}
$R$ の小数部分切り上げた順位 $t$ は次のようになります。(下記図解:手順3)
\begin{align*}
t &=8
\end{align*}
第8位のデータが75パーセンタイル $X$ になります。(下記図解:手順4)
\begin{align*}
X=x_8 = 17
\end{align*}
以下、上記計算の図解になります。
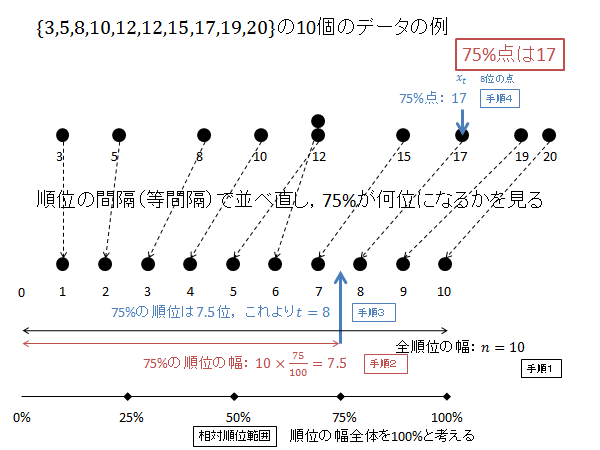
| データ | 順位 | 相対順位 | 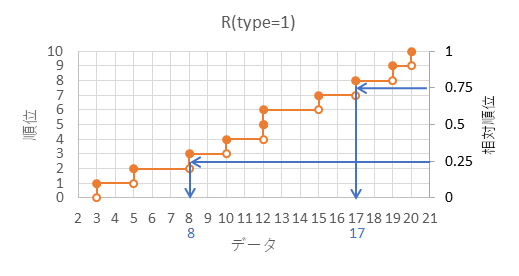 |
|---|
| 3 | 1 | 1/10=0.1 |
| 5 | 2 | 2/10=0.2 |
| 8 | 3 | 3/10=0.3 |
| 10 | 4 | 4/10=0.4 |
| 12 | 5 | 5/10=0.5 |
| 12 | 6 | 6/10=0.6 |
| 15 | 7 | 7/10=0.7 |
| 17 | 8 | 8/10=0.8 |
| 19 | 9 | 9/10=0.9 |
| 20 | 10 | 10/10=1.0 |
図のように、25%の相対順位に対応するデータの数値が25パーセンタイル、75%の相対順位に対応するデータの数値が75パーセンタイル、になり、他の分位数も綺麗に線を引くことで求めることが可能です。
R のコンソール画面で、次の赤字のように x にデータセットを指定し、prob に知りたい分位数の相対順位を指定します。
更に、type=1 のオプションを指定すると、青字の答えが返ってきます。
0% は最小値になるように補正を行っています。
> quantile(x=c(3,5,8,10,12,12,15,17,19,20),probs=c(0,0.25,0.50,0.75,1),type=1)
0% 25% 50% 75% 100%
3 8 12 17 20
また、後の type=2 との比較のために、次の計算結果を示しておきます。
> quantile(x=c(3,5,8,10,12,12,15,17,19,20),probs=c(0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9),type=1)
10% 20% 30% 40% 50% 60% 70% 80% 90%
3 5 8 10 12 12 15 17 19
R のコンソール画面で、次のように打ち込むと、type=1 の定義の分位数と相対順位の対応関係が分かります。
> data <- sort(c(3,5,8,10,12,12,15,17,19,20))
> p <- seq(from=0,to=1,by=0.0001)
> X <- quantile(x=data,probs=p,type=1)
> plot(x=X,y=p,pch=".",main="type=1")
> n <- length(data)
> pd <- seq_along(data)/n
> Xd <- quantile(x=data,probs=pd,type=1)
> points(x=Xd,y=pd,pch=16)
> abline(h=c(0,0.25,0.5,0.75,1),lty=2)
中央値は次のようになります。
相対順位 $p=\frac{1}{2}$ での順位 $R$ は次のようになる。
\begin{align*}
R=\frac{n}{2}
\end{align*}
データ数 $n$ が偶数の時は、$R$ を切り上げた $t$ は
\begin{align*}
t &=\frac{n}{2}
\end{align*}
となるので、中央値 $X$ は次のようになります。
\begin{align*}
X = x_{\frac{n}{2}}
\end{align*}
データ数 $n$ が奇数の時は、$R$ を切り上げた $t$ は
\begin{align*}
t &=\frac{n+1}{2}
\end{align*}
となるので、中央値(50パーセンタイル)$X$ は次のようになります。
\begin{align*}
X = x_{\frac{n+1}{2}}
\end{align*}
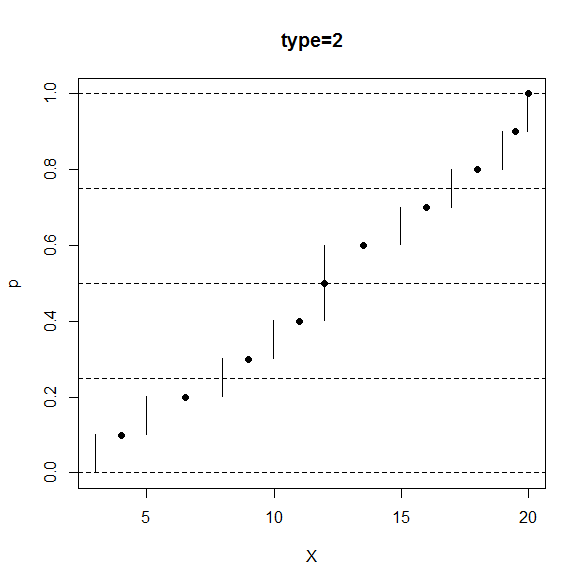
この type=2 は、前の type=1 とほとんど同じです。
違いは「順位が自然数になる所は、中間データを用いて繋いでいる」部分です。
type=1 よりも、非対称性が緩和される部分が良い所だと思います。
分位数やパーセンタイルの type=2 流の定義は次のものです。
(iv) の部分に場合分けがあります。
- 大きさ順に並べ替えた $n$ 個のデータ $x_i,\, i=1,2,\ldots, n$ を用意する。
\begin{align*}
x_1\le x_2\le \cdots \le x_n
\end{align*}
- 順位 $R$ を、相対順位 $p$ を使って次のように定義する。
\begin{align*}
R=np
\end{align*}
$p$ の範囲は、$0\lt p\le 1$ になります。
この範囲である相対順位範囲に $0$ は含まれません。
- $R$ の小数部分を切り上げた値を $t$ とする。
-
- $R$ に小数部分があり、切り上げが起こった場合
相対順位 $p$ での分位数(パーセンタイル)$X$ は次のようになる。
\begin{align*}
X=x_t
\end{align*}
- $R$ に小数部分がなく、切り上げが起こらなかった場合
相対順位 $p$ での分位数(パーセンタイル)$X$ は次のようになる。
\begin{align*}
X=\frac{x_R+x_{R+1}}{2}
\end{align*}
例として、$\{3, 5, 8, 10, 12, 12, 15, 17, 19, 20\}$ の10個のデータの分位数(パーセンタイル)を求めてみましょう。
$n=10$, $x_1=3$, $x_2=5$, $x_3=8$, $x_4=10$, $x_5=12$, $x_6=12$, $x_7=15$, $x_8=17$, $x_9=19$, $x_{10}=20$ です。
(20パーセンタイル)を計算するには次枠のように計算します。
$p=0.2$ の時の $X$ を求めます。
相対順位 20% の順位 $R$ を求めます。(下記図解:手順1、手順2)
\begin{align*}
R=10\times 0.2=2
\end{align*}
$R$ に小数部分がないので、切り上げは起こりません。(下記図解:手順3)
\begin{align*}
R &=2
\end{align*}
第2位と第3位の中間データ(0.5内分点)が20パーセンタイル $X$ になります。(下記図解:手順4)
\begin{align*}
X=\frac{x_2+x_3}{2} = \frac{5+8}{2}=6.5
\end{align*}
以下、上記計算の図解になります。
R のコンソール画面で、次の赤字のように x にデータセットを指定し、prob に知りたい分位数の相対順位を指定します。
更に、type=2 のオプションを指定すると、青字の答えが返ってきます。
0% は最小値になるように補正を行っています。
> quantile(x=c(3,5,8,10,12,12,15,17,19,20),probs=c(0,0.25,0.50,0.75,1),type=2)
0% 25% 50% 75% 100%
3 8 12 17 20
また、前の type=1 との比較のために、次の計算結果を示しておきます。
> quantile(x=c(3,5,8,10,12,12,15,17,19,20),probs=c(0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9),type=2)
10% 20% 30% 40% 50% 60% 70% 80% 90%
4.0 6.5 9.0 11.0 12.0 13.5 16.0 18.0 19.5
R のコンソール画面で、次のように打ち込むと、type=2 の定義の分位数と相対順位の対応関係が分かります。
> data <- sort(c(3,5,8,10,12,12,15,17,19,20))
> p <- seq(from=0,to=1,by=0.0001)
> X <- quantile(x=data,probs=p,type=2)
> plot(x=X,y=p,pch=".",main="type=2")
> n <- length(data)
> pd <- seq_along(data)/n
> Xd <- quantile(x=data,probs=pd,type=2)
> points(x=Xd,y=pd,pch=16)
> abline(h=c(0,0.25,0.5,0.75,1),lty=2)
中央値(50パーセンタイル)は次のようになり、通常の定義と同じになります。
相対順位 $p=\frac{1}{2}$ での順位 $R$ は次のようになる。
\begin{align*}
R=\frac{n}{2}
\end{align*}
データ数 $n$ が偶数の時は、$R$ に切り上げが起こらないので、中央値 $X$ は次のようになります。
\begin{align*}
X = \frac{x_{\frac{n}{2}}+x_{\frac{n}{2}+1}}{2}
\end{align*}
データ数 $n$ が奇数の時は、$R$ を切り上げた $t$ は
\begin{align*}
t &=\frac{n+1}{2}
\end{align*}
となるので、中央値(50パーセンタイル)$X$ は次のようになります。
\begin{align*}
X = x_{\frac{n+1}{2}}
\end{align*}
この辺りが type=1 よりも良い部分だと思われます。
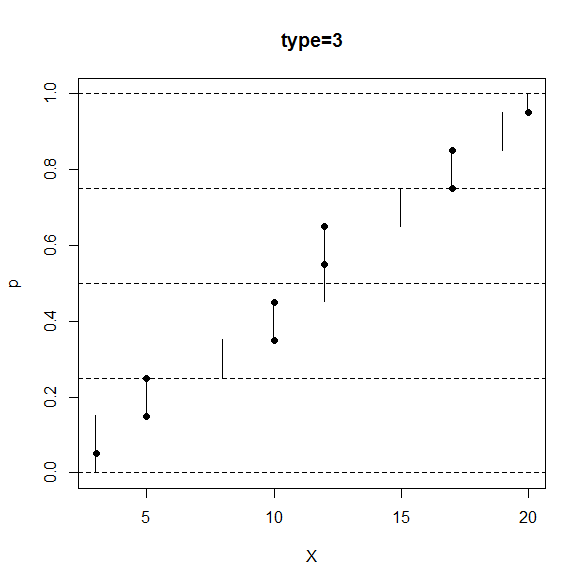
分位数やパーセンタイルの type=3 流の定義は次のものです。
(iv) の部分に場合分けがあります。
- 大きさ順に並べ替えた $n$ 個のデータ $x_i,\, i=1,2,\ldots, n$ を用意する。
\begin{align*}
x_1\le x_2\le \cdots \le x_n
\end{align*}
- 順位 $R$ を、相対順位 $p$ を使って次のように定義する。
\begin{align*}
R=\frac{1}{2}+np
\end{align*}
$p$ の範囲は、$0\lt p\lt 1$ になります。
この範囲である相対順位範囲に $0$ は含まれません。
- $R$ の整数部分を $r$ 、小数部分を $s$ とする。
-
- $s=0$ で、かつ、$r$ が $1$ じゃない奇数の場合
相対順位 $p$ での分位数(パーセンタイル)$X$ は次のようになる。
\begin{align*}
X=x_{r-1}
\end{align*}
- それ以外の場合
相対順位 $p$ での分位数(パーセンタイル)$X$ は次のようになる。
\begin{align*}
X=x_r
\end{align*}
例として、$\{3, 5, 8, 10, 12, 12, 15, 17, 19, 20\}$ の10個のデータの分位数(パーセンタイル)を求めてみましょう。
$n=10$, $x_1=3$, $x_2=5$, $x_3=8$, $x_4=10$, $x_5=12$, $x_6=12$, $x_7=15$, $x_8=17$, $x_9=19$, $x_{10}=20$ です。
第1四分位数(25パーセンタイル)を計算するには次枠のように計算します。
$p=0.25$ の時の $X$ を求めます。
相対順位 25% の順位 $R$ を求めます。
\begin{align*}
R=\frac{1}{2}+10\times\frac{25}{100}=0.5+2.5=3
\end{align*}
$R$ の整数部分 $r$ 、小数部分 $s$ は次のようになります。
\begin{align*}
r &=3 \\
s &=0.0
\end{align*}
$s=0$ で、かつ、$r$ が $1$ じゃない奇数なので、$r-1$ 位の点が25パーセンタイル $X$ になります。
\begin{align*}
X=x_2 = 5
\end{align*}
第3四分位数(75パーセンタイル)を計算するには次枠のように計算します。
$p=0.75$ の時の $X$ を求めます。
相対順位 75% の順位 $R$ を求めます。
\begin{align*}
R=\frac{1}{2}+10\times\frac{75}{100}=0.5+7.5=8
\end{align*}
$R$ の整数部分 $r$ 、小数部分 $s$ は次のようになります。
\begin{align*}
r &=8\\
s &=0.0
\end{align*}
$s=0$ ですが、$r$ が偶数なので、$r$ 位の点が75パーセンタイル $X$ になります。
\begin{align*}
X=x_8 = 17
\end{align*}
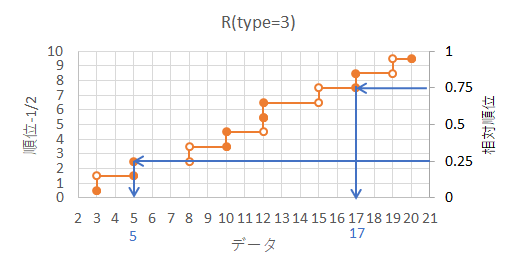
type=3 では type=5 と同じ順位と相対順位でグラフを描くのですが、type=5 と違って階段状に点を繋ぎます。
また、データ点での黒丸は、1位以外の奇数順位では左側の偶数順位の位置に打ちます。R のコンソール画面で「?quantile」と打ち込むと出てくるマニュアルでは「SAS definition: nearest even order statistic.」となっています。type=2 では、偶奇に関係なく中間に寄せていたのですが、それと似たような効果があるのだと思われます。
図のように、25%の相対順位に対応するデータの数値が25パーセンタイル、75%の相対順位に対応するデータの数値が75パーセンタイル、になり、他の分位数も綺麗に線を引くことで求めることが可能です。
R のコンソール画面で、次の赤字のように x にデータセットを指定し、prob に知りたい分位数の相対順位を指定します。
更に、type=3 のオプションを指定すると、青字の答えが返ってきます。
> quantile(x=c(3,5,8,10,12,12,15,17,19,20),probs=c(0,0.25,0.50,0.75,1),type=3)
0% 25% 50% 75% 100%
3 5 12 17 20
また、前の type=1,2 との比較のために、次の計算結果を示しておきます。
> quantile(x=c(3,5,8,10,12,12,15,17,19,20),probs=c(0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9),type=3)
10% 20% 30% 40% 50% 60% 70% 80% 90%
3 5 8 10 12 12 15 17 19
R のコンソール画面で、次のように打ち込むと、type=3 の定義の分位数と相対順位の対応関係が分かります。
> data <- sort(c(3,5,8,10,12,12,15,17,19,20))
> p <- seq(from=0,to=1,by=0.0001)
> X <- quantile(x=data,probs=p,type=3)
> plot(x=X,y=p,pch=".",main="type=3")
> n <- length(data)
> pd <- (seq_along(data)-1/2)/n
> Xd <- quantile(x=data,probs=pd,type=3)
> points(x=Xd,y=pd,pch=16)
> abline(h=c(0,0.25,0.5,0.75,1),lty=3)
Python の NumPy ライブラリに percentile 関数があり、これを使うことでパーセンタイルが計算できます。
この関数の仕様が (こちら) にあります。
いったいどのような定義になっているのか?
NumPy と matplotlib ライブラリをインストールした Python のインタプリタで、次の命令を順次実行すると、分位数と相対順位の関係が分かります。
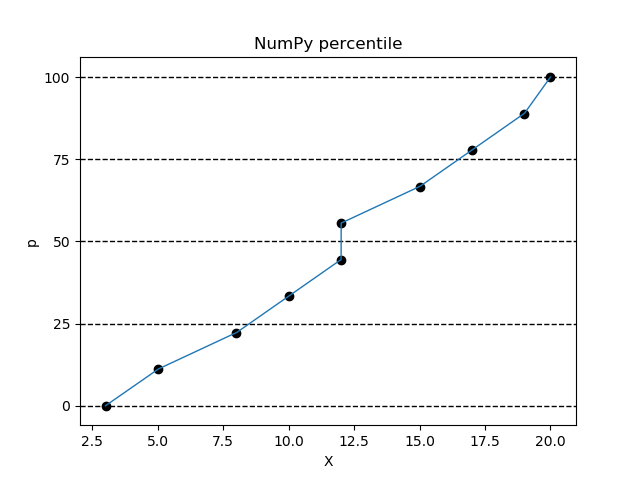
Excel の .INC タイプ、R の type=7 と同じタイプの定義になります。
>>> import numpy as np
>>> data = sorted([3,5,8,10,12,12,15,17,19,20])
>>> p = [x/10000*100 for x in range(0,10001)]
>>> X = np.percentile(a=data,q=p)
>>> n = len(data)
>>> pd = [(x-1)/(n-1)*100 for x in range(1,n+1)]
>>> import matplotlib.pyplot as plt
>>> ax = plt.figure().add_subplot(1,1,1)
>>> plt.plot(X,p,linewidth=1)
>>> ax.set_yticks([0,25,50,75,100])
>>> ax.grid(axis='y',color='black',lw=1,linestyle='dashed')
>>> plt.scatter(data,pd,color='black')
>>> plt.title('NumPy percentile')
>>> plt.xlabel('X')
>>> plt.ylabel('p')
>>> plt.show()
この関数には interpolation というオプションがあり、このオプションを変えることで、データポイントの間の補間のやり方を変えることができます。
Python のインタプリタで、次の命令を順次実行してみてください。
>>> import numpy as np
>>> data = sorted([3,5,8,10,12,12,15,17,19,20])
>>> p = [x/10000*100 for x in range(0,10001)]
>>> X1 = np.percentile(a=data,q=p,interpolation='linear')
>>> X2 = np.percentile(a=data,q=p,interpolation='higher')
>>> X3 = np.percentile(a=data,q=p,interpolation='lower')
>>> X4 = np.percentile(a=data,q=p,interpolation='nearest')
>>> X5 = np.percentile(a=data,q=p,interpolation='midpoint')
>>> n = len(data)
>>> pd = [(x-1)/(n-1)*100 for x in range(1,n+1)]
>>> import matplotlib.pyplot as plt
>>> ax = plt.figure().add_subplot(1,1,1)
>>> plt.plot(X1,p,linewidth=1,label='linear')
>>> plt.plot(X2,p,linewidth=1,label='higher',linestyle='--')
>>> plt.plot(X3,p,linewidth=1,label='lower',linestyle='--')
>>> plt.plot(X4,p,linewidth=1,label='nearest',linestyle='-.')
>>> plt.plot(X5,p,linewidth=1,label='midpoint',linestyle='-.')
>>> ax.set_yticks([0,25,50,75,100])
>>> ax.grid(axis='y',color='lightgray',lw=1)
>>> plt.scatter(data,pd,color='black')
>>> plt.title('NumPy percentile')
>>> plt.xlabel('X')
>>> plt.ylabel('p')
>>> plt.legend(loc='lower right',framealpha=1)
>>> plt.show()
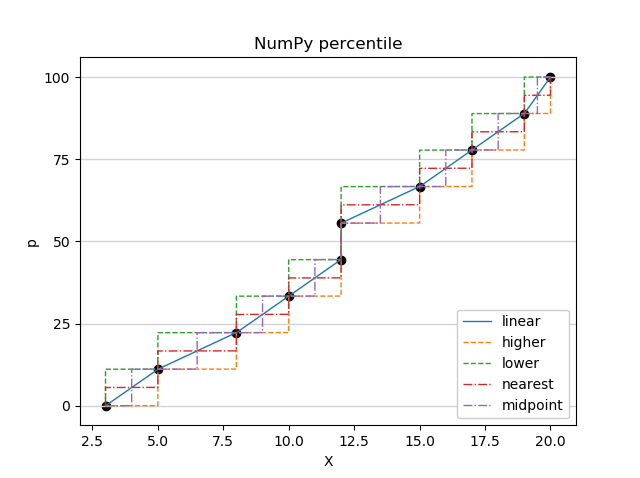
「linear:線形」、「higher:大きい方の値」、「lower:小さい方の値」、「nearest:近い方の値」、「midpoint:中間の値」でデータが存在しない位置のパーセンタイルを補間します。
Python の SciPy パッケージの stat モジュールの Masked statistics 関数群に、mquantiles 関数があり、これを使うことでパーセンタイルが計算できます。
この関数の仕様が (こちら) にあります。
この関数では $n$ 個のデータの順位 $R$ と相対順位 $p$ の関係は次の(ii)のように、パラメータ $\alpha$ と $\beta$ の設定によって変えられるようになっています。
- 大きさ順に並べ替えた $n$ 個のデータ $x_i,\, i=1,2,\ldots, n$ を用意する。
\begin{align*}
x_1\le x_2\le \cdots \le x_n
\end{align*}
- 順位 $R$ を、相対順位 $p$ を使って次のように定義する。
\begin{align*}
R=\alpha + \left(n + 1 - \alpha - \beta\right)p
\end{align*}
- $R$ の整数部分を $r$ 、小数部分を $s$ とする。
- 相対順位 $p$ での分位数(パーセンタイル)$X$ は次のようになる。
\begin{align*}
X=x_r+s\left(x_{r+1}-x_{r}\right)
\end{align*}
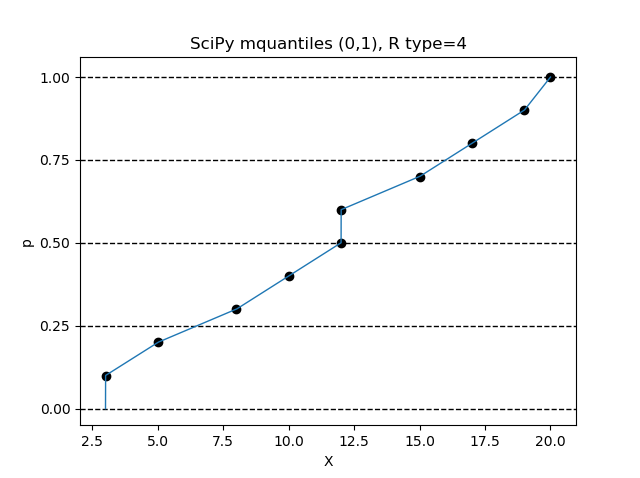
$(\alpha, \beta) = (0, 1)$ の設定で、R言語の type=4 の設定と同じになります。
Python のインタプリタで、次の命令を順次実行してみてください。
>>> from scipy.stats.mstats import mquantiles
>>> data = sorted([3,5,8,10,12,12,15,17,19,20])
>>> p = [x/10000 for x in range(0,10001)]
>>> X = mquantiles(a=data,prob=p,alphap=0,betap=1)
>>> n = len(data)
>>> pd = [x/n for x in range(1,n+1)]
>>> import matplotlib.pyplot as plt
>>> ax = plt.figure().add_subplot(1,1,1)
>>> plt.plot(X,p,linewidth=1)
>>> ax.set_yticks([0,0.25,0.5,0.75,1])
>>> ax.grid(axis='y',color='black',lw=1,linestyle='dashed')
>>> plt.scatter(data,pd,color='black')
>>> plt.title('SciPy mquantiles (0,1), R type=4')
>>> plt.xlabel('X')
>>> plt.ylabel('p')
>>> plt.show()
$(\alpha, \beta) = (1/2, 1/2)$ の設定で、R言語の type=5 の設定と同じになります。
Python のインタプリタで、次の命令を順次実行してみてください。
>>> from scipy.stats.mstats import mquantiles
>>> data = sorted([3,5,8,10,12,12,15,17,19,20])
>>> p = [x/10000 for x in range(0,10001)]
>>> X = mquantiles(a=data,prob=p,alphap=1/2,betap=1/2)
>>> n = len(data)
>>> pd = [(x-1/2)/n for x in range(1,n+1)]
>>> import matplotlib.pyplot as plt
>>> ax = plt.figure().add_subplot(1,1,1)
>>> plt.plot(X,p,linewidth=1)
>>> ax.set_yticks([0,0.25,0.5,0.75,1])
>>> ax.grid(axis='y',color='black',lw=1,linestyle='dashed')
>>> plt.scatter(data,pd,color='black')
>>> plt.title('SciPy mquantiles (1/2,1/2), R type=5')
>>> plt.xlabel('X')
>>> plt.ylabel('p')
>>> plt.show()
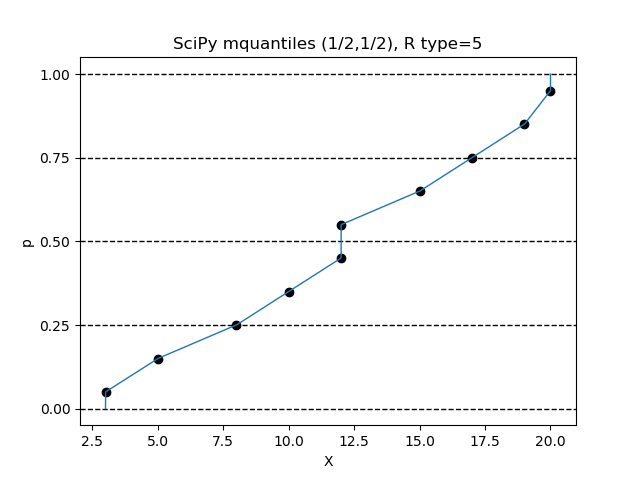
$(\alpha, \beta) = (0, 0)$ の設定で、R言語の type=6 の設定と同じになります。
Python のインタプリタで、次の命令を順次実行してみてください。
>>> from scipy.stats.mstats import mquantiles
>>> data = sorted([3,5,8,10,12,12,15,17,19,20])
>>> p = [x/10000 for x in range(0,10001)]
>>> X = mquantiles(a=data,prob=p,alphap=0,betap=0)
>>> n = len(data)
>>> pd = [x/(n+1) for x in range(1,n+1)]
>>> import matplotlib.pyplot as plt
>>> ax = plt.figure().add_subplot(1,1,1)
>>> plt.plot(X,p,linewidth=1)
>>> ax.set_yticks([0,0.25,0.5,0.75,1])
>>> ax.grid(axis='y',color='black',lw=1,linestyle='dashed')
>>> plt.scatter(data,pd,color='black')
>>> plt.title('SciPy mquantiles (0,0), R type=6')
>>> plt.xlabel('X')
>>> plt.ylabel('p')
>>> plt.show()
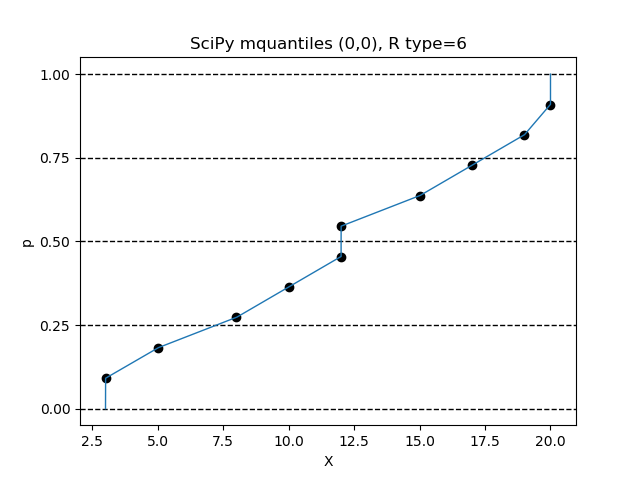
$(\alpha, \beta) = (1, 1)$ の設定で、R言語の type=7 の設定と同じになります。
Python のインタプリタで、次の命令を順次実行してみてください。
>>> from scipy.stats.mstats import mquantiles
>>> data = sorted([3,5,8,10,12,12,15,17,19,20])
>>> p = [x/10000 for x in range(0,10001)]
>>> X = mquantiles(a=data,prob=p,alphap=1,betap=1)
>>> n = len(data)
>>> pd = [(x-1)/(n-1) for x in range(1,n+1)]
>>> import matplotlib.pyplot as plt
>>> ax = plt.figure().add_subplot(1,1,1)
>>> plt.plot(X,p,linewidth=1)
>>> ax.set_yticks([0,0.25,0.5,0.75,1])
>>> ax.grid(axis='y',color='black',lw=1,linestyle='dashed')
>>> plt.scatter(data,pd,color='black')
>>> plt.title('SciPy mquantiles (1,1), R type=7')
>>> plt.xlabel('X')
>>> plt.ylabel('p')
>>> plt.show()
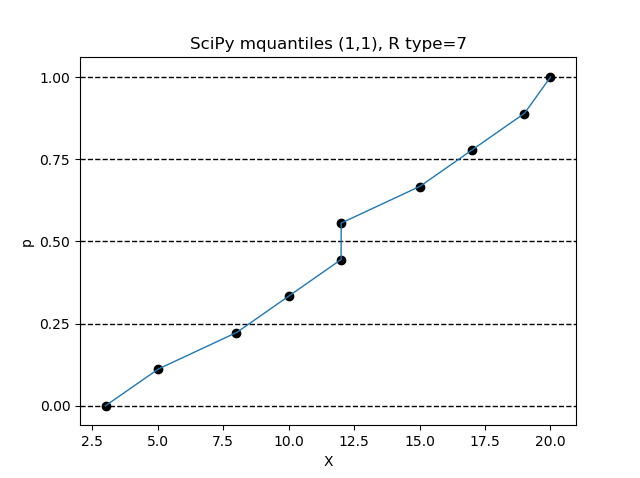
$(\alpha, \beta) = (1/3, 1/3)$ の設定で、R言語の type=8 の設定と同じになります。
Python のインタプリタで、次の命令を順次実行してみてください。
>>> from scipy.stats.mstats import mquantiles
>>> data = sorted([3,5,8,10,12,12,15,17,19,20])
>>> p = [x/10000 for x in range(0,10001)]
>>> X = mquantiles(a=data,prob=p,alphap=1/3,betap=1/3)
>>> n = len(data)
>>> pd = [(x-1/3)/(n+1/3) for x in range(1,n+1)]
>>> import matplotlib.pyplot as plt
>>> ax = plt.figure().add_subplot(1,1,1)
>>> plt.plot(X,p,linewidth=1)
>>> ax.set_yticks([0,0.25,0.5,0.75,1])
>>> ax.grid(axis='y',color='black',lw=1,linestyle='dashed')
>>> plt.scatter(data,pd,color='black')
>>> plt.title('SciPy mquantiles (1/3,1/3), R type=8')
>>> plt.xlabel('X')
>>> plt.ylabel('p')
>>> plt.show()
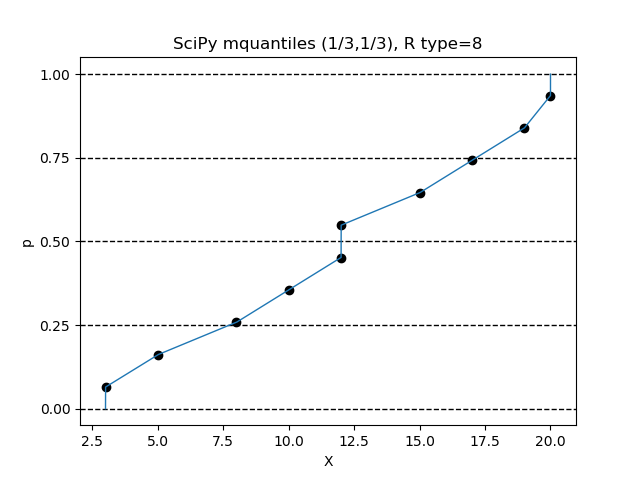
$(\alpha, \beta) = (3/8, 3/8)$ の設定で、R言語の type=9 の設定と同じになります。
Python のインタプリタで、次の命令を順次実行してみてください。
>>> from scipy.stats.mstats import mquantiles
>>> data = sorted([3,5,8,10,12,12,15,17,19,20])
>>> p = [x/10000 for x in range(0,10001)]
>>> X = mquantiles(a=data,prob=p,alphap=3/8,betap=3/8)
>>> n = len(data)
>>> pd = [(x-3/8)/(n+1/4) for x in range(1,n+1)]
>>> import matplotlib.pyplot as plt
>>> ax = plt.figure().add_subplot(1,1,1)
>>> plt.plot(X,p,linewidth=1)
>>> ax.set_yticks([0,0.25,0.5,0.75,1])
>>> ax.grid(axis='y',color='black',lw=1,linestyle='dashed')
>>> plt.scatter(data,pd,color='black')
>>> plt.title('SciPy mquantiles (3/8,3/8), R type=9')
>>> plt.xlabel('X')
>>> plt.ylabel('p')
>>> plt.show()
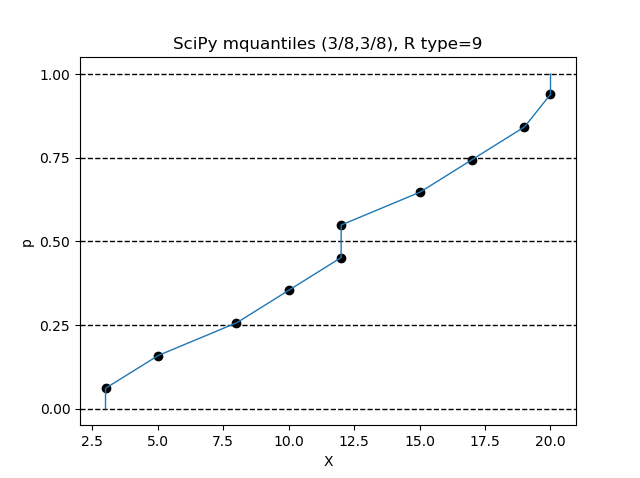
$(\alpha, \beta) = (2/5, 2/5)$ の設定が、この関数のデフォルト値です。
Python のインタプリタで、次の命令を順次実行してみてください。
>>> from scipy.stats.mstats import mquantiles
>>> data = sorted([3,5,8,10,12,12,15,17,19,20])
>>> p = [x/10000 for x in range(0,10001)]
>>> X = mquantiles(a=data,prob=p)
>>> n = len(data)
>>> pd = [(x-2/5)/(n+1/5) for x in range(1,n+1)]
>>> import matplotlib.pyplot as plt
>>> ax = plt.figure().add_subplot(1,1,1)
>>> plt.plot(X,p,linewidth=1)
>>> ax.set_yticks([0,0.25,0.5,0.75,1])
>>> ax.grid(axis='y',color='black',lw=1,linestyle='dashed')
>>> plt.scatter(data,pd,color='black')
>>> plt.title('SciPy mquantiles (2/5,2/5), default')
>>> plt.xlabel('X')
>>> plt.ylabel('p')
>>> plt.show()
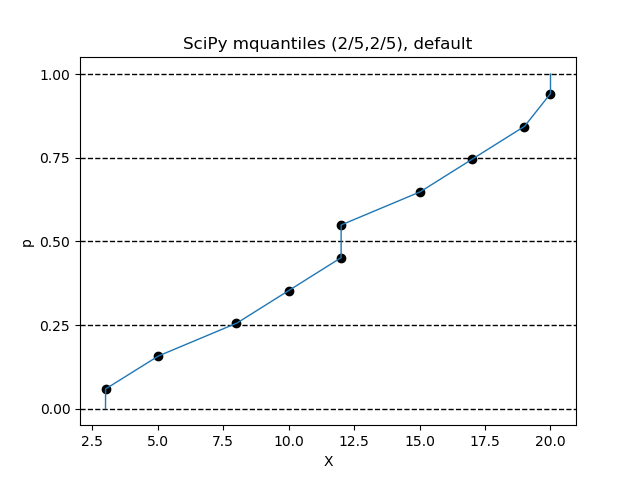
この設定がデフォルトになっているのは、正規分布に従うデータかどうかの判定をやりやすくするためです。
詳しくは(この論文)や、(この解説)を参考にしてください。